更新:2026-02-06 11:06:32
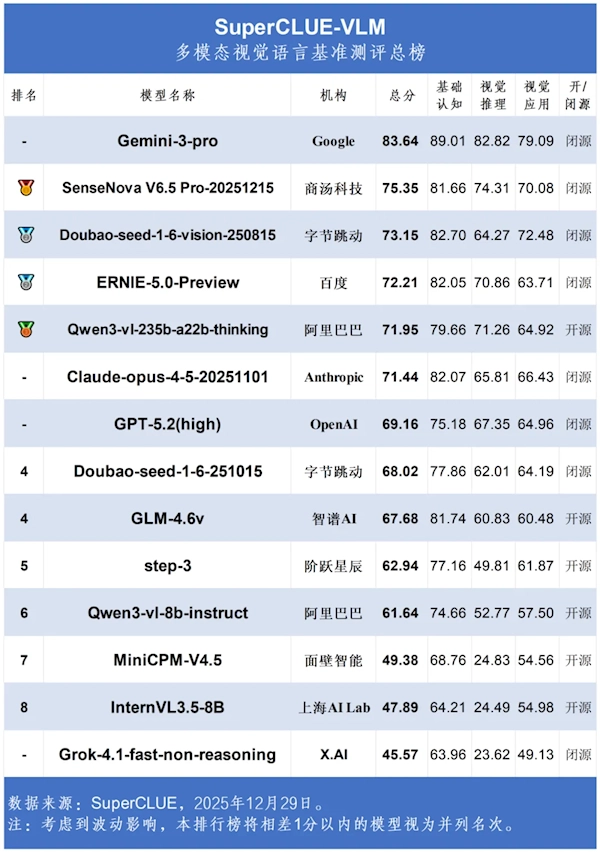
12月31日消息,近日,SuperCLUE-VLM多模态视觉语言基准测评12月总榜已正式公布。
谷歌的Gemini-3-pro以83.64分的成绩大幅领先,字节跳动的豆包大模型则以73.15分进入前三名,这体现出了国内大模型所具备的竞争力。
此次评估从基础认知、视觉推理、视觉应用这三个维度对多模态大模型展开测评。
位居榜首的Gemini-3-pro在三项细分指标上都展现出卓越表现,其中基础认知得分为89.01分、视觉推理82.82分、视觉应用79.09分,在各方面均领先于其他模型。

在国内阵营里,商汤科技的SenseNova V6.5 Pro拿到75.35分,排在第二位;字节跳动的豆包视觉版则紧跟其后,它的基础认知得分达到82.70分,这一成绩甚至比部分国际竞品还要出色,只是在视觉推理这一环节上略有些不足。
百度ERNIE-5.0-Preview、阿里巴巴Qwen3-vl等国内模型同样跻身前五,值得一提的是,Qwen3-vl是该榜单中首个实现开源且总分突破70分的模型。
在国际头部模型的评分中,Anthropic旗下的Claude-opus-4-5取得了71.44分的成绩,而OpenAI的GPT-5.2(high)仅获得69.16分,在排名上处于相对靠后的位置。